
In today’s hyper-connected digital landscape, social media platforms process billions of interactions every minute—from likes and shares to live streams and direct messages. Behind the scenes, a critical—but often overlooked—technical process keeps this data flowing smoothly: data spooling. While the term “spooling” may sound like jargon from the printing era, its modern application in social media infrastructure is essential for performance, scalability, and user experience.
But what exactly is data spooling in the context of social media? How does it differ from traditional spooling? And why should marketers, developers, or platform architects care?
This article unpacks the concept of data spooling in social media, explains its technical underpinnings, explores real-world use cases, and clarifies common misconceptions. Whether you’re a tech-savvy content creator or a backend engineer, understanding this mechanism can help you optimize workflows and anticipate system behavior.

Understanding Data Spooling: Definition and Core Principles
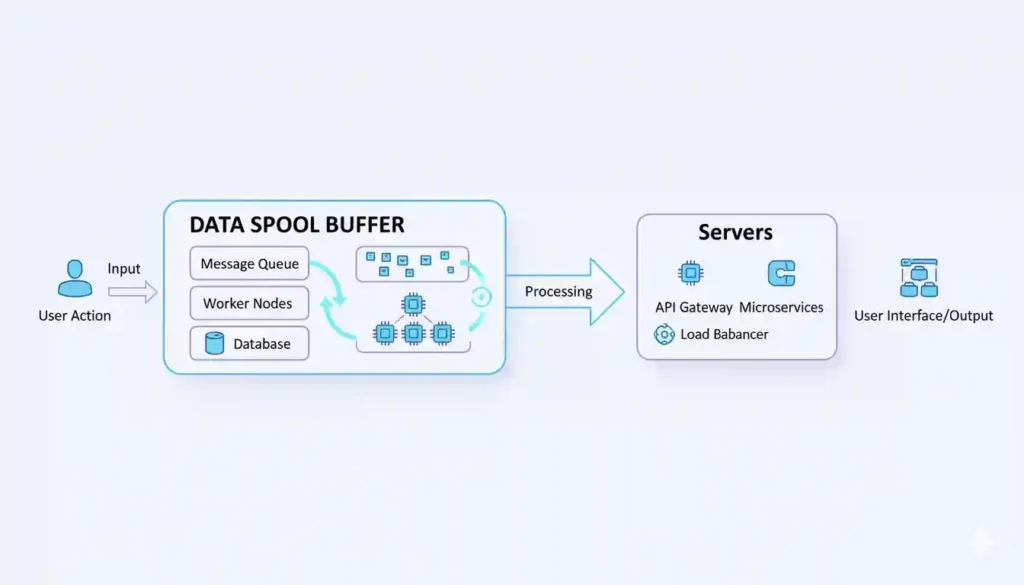
At its core, data spooling (Simultaneous Peripheral Operations On-Line) refers to the temporary storage of data in a buffer or queue before it’s processed or transmitted. Originally developed to manage slow input/output devices like printers, spooling has evolved into a foundational technique in distributed systems—including social media platforms.
In social media, data spooling ensures that high-volume, real-time actions (e.g., posting a story, uploading a video, or sending a DM) don’t overwhelm backend services. Instead of processing each request instantly, the system “spools” it into a temporary holding area—often a message queue like Apache Kafka or RabbitMQ—where it waits its turn for orderly, efficient handling.
This decoupling of input and processing prevents bottlenecks, reduces latency for end users, and allows platforms to scale horizontally during traffic spikes (e.g., during viral trends or live events).

How Data Spooling Powers Social Media Platforms
Major platforms like Facebook, X (formerly Twitter), and TikTok rely on spooling mechanisms to manage massive data loads. Consider a live-streamed concert with millions of concurrent viewers: every comment, like, and share must be captured, validated, and displayed in near real time.
Without spooling, the system would either crash under load or deliver a laggy, inconsistent experience. Instead, incoming interactions are spooled into high-throughput queues. Background workers then consume these queued items at a sustainable pace, applying business logic (e.g., spam filtering, content moderation, analytics tagging) before persisting data to databases or pushing updates to users.
Spooling also enables asynchronous processing, which is crucial for features like scheduled posts, batch analytics, or AI-driven content recommendations. By decoupling user actions from immediate execution, platforms gain flexibility, fault tolerance, and smoother user experiences.

Common Misconceptions About Data Spooling in Social Media
Many confuse data spooling with caching, buffering, or simple queuing—but there are nuanced differences:
- Caching stores frequently accessed data for faster retrieval (read optimization).
- Buffering temporarily holds data during transfer (e.g., video streaming).
- Spooling specifically manages job-like tasks that require sequential or batched processing (write/execution optimization).
Another myth: spooling introduces unnecessary delays. In reality, well-designed spooling systems minimize perceived latency by prioritizing critical tasks (e.g., direct messages over analytics logging) and using parallel consumers.
Also, spooling isn’t just for giants like Meta or YouTube. Even mid-sized social apps use lightweight spooling via cloud services (e.g., AWS SQS, Google Pub/Sub) to handle user-generated content reliably.
Real-World Benefits and Use Cases
Data spooling delivers tangible advantages across social media operations:
- Scalability: Handle viral content surges without service degradation.
- Reliability: If a processing node fails, spooled data remains queued for retry.
- Modularity: Teams can update or replace processing logic without disrupting input streams.
- Compliance: Spooled data can be audited or redacted before final storage (useful for GDPR or content moderation).
For example, when you schedule a post on LinkedIn, it’s spooled until the designated time. Similarly, Instagram may spool photo uploads while applying filters or AI enhancements in the background.
Developers also use spooling to stage A/B test variants, log user behavior for analytics, or feed data into machine learning pipelines—all without blocking the user interface.
Frequently Asked Questions (LSI Keywords Integrated)
Q1: What is the difference between spooling and queuing in social media systems?
While often used interchangeably, queuing is a broader concept. Spooling is a specific type of queuing optimized for I/O-bound tasks with temporary storage.
Q2: Does data spooling affect user privacy on social platforms?
Not inherently. However, since spooled data may reside temporarily in logs or queues, proper encryption and access controls are essential to protect sensitive information.
Q3: Can spooling cause data loss?
Only if the spooling system lacks durability (e.g., in-memory queues without persistence). Production-grade systems use disk-backed or replicated queues to prevent loss.
Q4: How do social media companies monitor spooling performance?
Through metrics like queue depth, consumer lag, and processing latency—often visualized in dashboards like Grafana or Datadog.
Q5: Is data spooling used in AI-driven content moderation?
Yes. User reports or flagged posts are often spooled before being reviewed by AI models or human moderators, ensuring consistent workflow handling.
💡 My Opinion / Conclusion
As someone who closely follows digital infrastructure trends, I believe data spooling is one of the unsung heroes of modern social media. While users focus on algorithms, UI design, or engagement metrics, the real magic often happens in the background—where spooling quietly ensures that every tap, swipe, and share is handled with precision and resilience.
In an era where milliseconds impact retention and virality can crash unprepared systems, spooling provides the backbone for stability and scale. It’s not flashy, but it’s foundational. For developers, understanding spooling patterns can mean the difference between a scalable app and a fragile one. For non-technical stakeholders, recognizing its role fosters better collaboration with engineering teams.
Looking ahead, as AI agents and real-time interactivity become standard (think live co-creation or metaverse interactions), spooling will only grow in importance. The key is implementing it thoughtfully—with observability, security, and user experience in mind. In short: you may not see data spooling, but you’d definitely miss it if it weren’t there.


